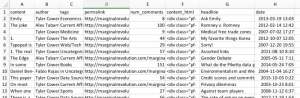
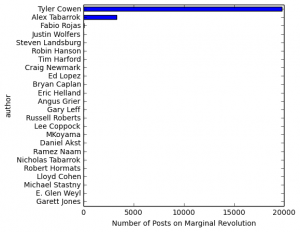
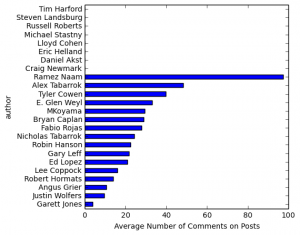
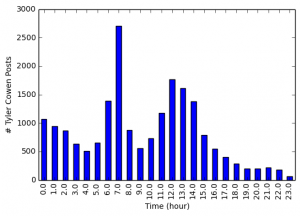
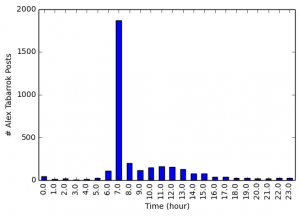
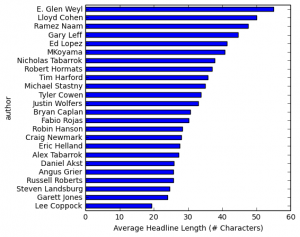
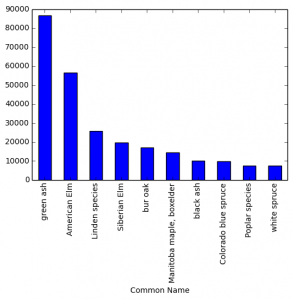
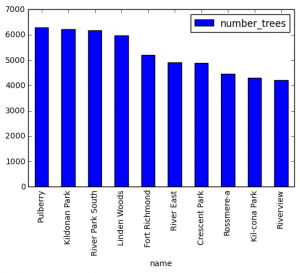
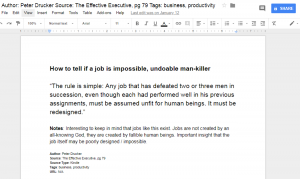
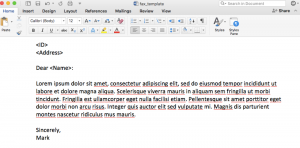
Very often, data needs to be understood on a geographic basis. As a result, data scientists should be familiar with the main mapping tools at their disposal.
I have done quite a bit of mapping before, but given its central nature in my current position as a Transportation Assets Data Scientist with the City of Winnipeg, it quickly became clear that I need to do a careful survey of the geographic mapping landscape.
There is a dizzying array of options out there. Given my main programming language is python, I’ll start with tools in that ecosystem, but then I’ll move on to other software tools available for geographic analysis.
Mapping Tools in Python
GeoPandas is a fantastic library that that makes munging geographic data in Python easy.
At its core, it is essentially pandas (a must-know library for any data scientist working with python). In fact, it is actually built on top of pandas, with data structures like “GeoSeries” and “GeoDataFrame” that extend the equivalent pandas data structures with useful geographic data crunching features. So, you get all the goodness of pandas, with geographic capabilities baked in.
GeoPandas works its magic by combining the capabilities of several existing geographic data analysis libraries that are each worth being familiar with. This includes shapely, fiona, and built in geographic mapping capabilities through descartes and matplotlib.
You can read spatial data into GeoPandas just like pandas, and GeoPandas works with the geographic data formats you would expect, such as GeoJSON and ESRI Shapefiles. Once you have the data loaded, you can easily change projections, conduct geometric manipulations, aggregate data geographically, merge data with spatial joins, and conduct geocoding (which relies on the geocoding package geopy).
Basemap is a geographic plotting library built on top of matplotlib, which is the granddaddy of python plotting libraries. Similarly to matplotlib, basemap is quite powerful and flexible, but at the cost of being somewhat time consuming and cumbersome to get the map you want.
Another notable issue is that Basemap recently came under new management in 2016 and is going to be replaced by Cartopy (described below). Although Basemap will be maintained until 2020, the Matplotlib website indicates that all development efforts are now focused on Cartopy and users should switch to Cartopy. So, if you’re planning on using Basemap, consider using…..
Cartopy provides geometric transformation capabilities as well as mapping capabilities. Similarly to Basemap, Cartopy exposes an interface to matplotlib to create maps on your data. You get a lot of mapping power and flexibility coming from matplotlib, but the downside is similar: creating a nice looking map tends to be relatively more involved compared to other options, with more code and tinkering required to get what you want.
Geoplotlib is another geographic mapping option for Python that appears to be a highly flexible and powerful tool, allowing static map creation, as well as animated visualizations, and interactive maps. I have never used this library, and it appears to be relatively new, but it might be one to keep an eye out for in the future.
gmplot allows you to easily plot polygons, lines, and points on google maps, using a “matplotlib-like interface”. This allows you to quickly and easily plot your data and piggy-back on the interactivity inherent to Google Maps. Plots available include polygons with fills, drop pins, scatter points, grid lines, and heatmaps. It appears to be a great option for quick and simple interactive maps.
Mapnik is a toolkit written in C++ (with Python bindings) to produce serious mapping applications. It is aimed primarily at developing these mapping applications on the web. It appears to be a heavy duty tool that powers a lot of maps you see on the web today, including OpenStreetMap and MapBox.
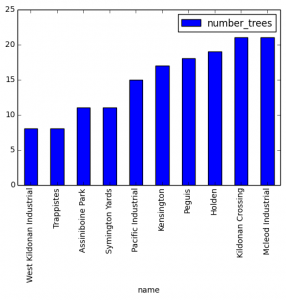
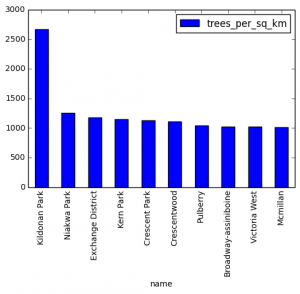
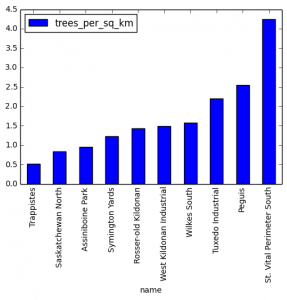
Folium lets you tap into the popular leaflet.js framework for creating interactive maps, without having to write a single line of JavaScript. It’s a great library that I have used quite often in recent months (I used folium to generate all the visualizations for my Winnipeg tree data blog post).
Folium allows you to map points, lines, and polygons, produce choropleth maps and heat maps, create map layers (that users can enable or disable themselves), and produce pop-up tooltips for your geographic data (bonus: these tooltips support html so you can really customize them to make them look nice). There is also a good amount of customization possible with the markers and lines used on your map.
Overall, Folium strikes a great balance between features, customizability, and ease of programming.
Plotly is a company offering a large suite of online data analytics and visualization tools. The focus of Plotly is providing frameworks that make it easier to present visualizations on the web. You write your code in Python (or R), talking to a plotly library and the visualizations are rendered using the extremely powerful D3.js library. For a taste of what is possible, check out their website, which showcases a bunch of mapping possibilities.
On top of the charts and mapping tools, they have a bunch of additional related products of interest on their website that are worth checking out. One that I’m particularly interested in is Dash, which allows you to create responsive data-driven web applications (mainly designed for dashboards) using only Python (no JavaScript or HTML required). This is something I’m definitely going to check out and will probably produce a “diving into data science” post in the near future.
Bokeh is a library specializing in interactive visualizations presented in the browser. This includes geographic data and maps. Similarly to Dash, there is also the possibility of using Bokeh to create interactive web applications that update data in real time and respond to user input (it does this with a “Bokeh Server”).
Other Tools for Mapping
There are obviously a huge amount of mapping tools outside of the python ecosystem. Here is a brief summary of a few that you might want to check out. Keep in mind that there are tons and tons of tools out there that are missing from this list. These are just some of the tools that I’m somewhat familiar with.
Kepler is a web-based application that allows you to explore geodata. It’s a brand spanking new tool released in late May 2018 by Uber. You can use the software live on its website – Kepler is a client side application with no server backend so all the data resides on your local machine / browser even. It’s not just for use in on the Kepler website however; you can install the application and run it on localhost or a server, and you can also embed it into your existing web applications.
The program has some great features, with most of the basic features you would expect in an interactive mapping application, plus some really great bonus features such as split maps and playback. The examples displayed on the website are quite beautiful and the software is easy to use (accessible for use non-programmers).
This user guide provides more information on Kepler, what it can do, and how to do it. I’m very much looking forward to checking it out for some upcoming projects.
Mapbox provides a suite of tools related to mapping, aimed at developers to help you create applications that use maps and spatial analysis. It provides a range of services, from creating a nice map for your website to helping you build a geoprocessing application.
This overview provides a good idea of what’s possible. Mapbox provides a bunch of basemap layers, allow you to customize your maps, add your own data, and build web and mobile applications. It also provides options for extending functionality of web apps with tools like geocoding, directions, spatial analysis, and other features. Although Mapbox is not a free service, they do seem to have generous free API call limits (see their pricing here).
Heavy Duty GIS Applications
Not included here but also really important for people doing mapping are the full fledged GIS applications such as ArcGIS and QGIS. These are extremely powerful tools that are worth knowing as a geodata analyst. Note that ArcGIS is quite expensive; however, it is an industry standard so worth knowing. QGIS is also fairly commonly used and has the advantage of being free and open source.
Any glaring ommissions in this post? Let me know in the comments below or send me an email.
Further resources
Python data visualization libraries
Essential Python Geospatial Libraries
So You’d Like to Make a Map Using Python
Visualizing Geographic Data With Python
Geospatial Data with Open Source Tools in Python (YouTube) and accompanying GitHub Repo of Notebooks
Basemap
Basemap Tutorial
Map Making in Python with Basemap
Mapnik
Mapnik Wiki
Mapnik – Maybe the Best Python Mapping Platform Yet
Take Control of Your Maps
Folium
Python tutorial on making a multilayer Leaflet web map with Folium (YouTube)
Interactive Maps with Python (Three Parts)
Creating Interactive Crime Maps with Folium
Bokeh
Python: mapping data with python library Bokeh
Interactive Maps with Bokeh