Here’s a problem I’ve had for a long time: I would invest a lot of time into reading a great book, then inevitably as time passed the insights I gained would slowly disappear from my mind. This was pretty discouraging to me and seemed to defeat the purpose of reading the book in the first place.
So, I was very excited to come across this blog post by Ryan Holiday on keeping a “commonplace book”: your own personal repository of important insights from the various sources you encounter throughout your life.
The source of these insights can come from anywhere, like books, blogs, speeches, interactions you’ve had with others, interesting situations you’ve been in, jokes, personal life stories, ideas, etc. I’ve been doing it for about a year and have added 220 notes and counting.
There are a bunch of benefits from keeping a commonplace book:
- You can easily review it and go back to categories of ideas as you encounter challenges in your life, and your commonplace book will have all the most important insights for you at your disposal, ready to go. For example, if you have a challenge with one of your kids, you have your “parenting” category in your commonplace book ready to go to provide you with support.
- You improve your reading skills by consolidating and condensing the most important and relevant material from your sources, as it forces you to think more carefully about what you’re reading and what it means.
- By reviewing and reflecting on your commonplace book entries, you improve your writing skills and increase your memory and comprehension about the materials you’ve read.
- You can use the quotes from your commonplace book to enhance in your own writing. For example, I’ve noticed Ryan Holiday’s writing liberally uses quotes from other sources. These often come from an extremely wide variety of sources and are really effective at supporting the points he is making in his writing. This is clearly the result of his voracious reading habits and commonplace book note-taking.
A commonplace book is like an investment that grows and grows over time. Much like a stock or bond, the earlier you invest, the bigger the payoff.
My commonplace book system
There are a million different ways that you can develop a commonplace book. There’s obviously no one “correct” way to do it, but hopefully my personal commonplace book system gives you some inspiration.
My system uses Google Docs, using a template designed to maximize my retention and reflection on the commonplace book notes and make the commonplace book easily searchable. The system also uses the Google Drive API to send myself daily emails each morning with commonplace book notes to review.
As much as possible, I’ve designed the system to take advantage of scientifically proven learning and retention techniques, including testing and recalling, spaced repetition, varied practice, and elaboration.
Aside: I highly recommend the book Make it Stick, which outlines the best evidence-supported study and learning methods and debunks a lot of common misconceptions, For example, re-reading passages and highlighting are horribly inefficient learning techniques.
My Template for Notes
Here is the template that I use for each of my commonplace book notes:
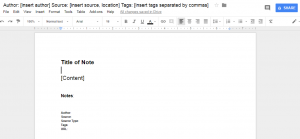
I make one of these notes for each important point or insight that I come across. For a good book packed with useful information, I’ll probably create about 10-20 of these notes. Each of the components of this template have a specific purpose:
- Title of Note: This typically labels the content of the note in some way to trigger my memory about what the passage is about. I try to make it somewhat vague so I don’t give away all the content. Then, when I review my notes, I’ll read only the title and then look away to try to recall what the passage is about. This is a way of incorporating testing and recall into my review. It helps improve retention and memory of the note and makes it more likely that I’ll have it in mind, ready to apply when the time is right.
- Content: The main content of the note – usually a quotation, but not always.
- Notes: A place where I can connect the content with existing knowledge and add any personal ideas or insights. Doing this kind of elaboration helps with understanding and retention.
- Citation information: The author, source, page, and url so I know exactly where each passage came from and can look it up or cite it easily if necessary. This also makes the notes way more searchable. Google Drive has great built-in search features (as you would expect), making it easy to find notes from a particular author, book, or tag.
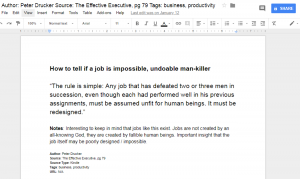
Here’s an example of a note I took from the business and management book The Effective Executive by Peter Drucker. I added this quote to my commonplace book because it had actually never really occurred to me that a job could be poorly designed and unfit for humans. Seemed like a good insight to keep in mind as a prospective employee and if I’m ever in the position of creating job positions myself.
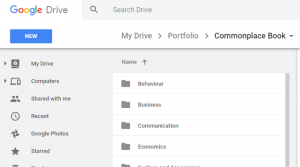
The Folder System
I divide my notes into folders and subfolders related to the topic. Often, one note could fit in more than one folder. To solve this problem, I make sure to write tags in the filename, and then randomly pick one of the relevant folders to put it in. Using tags, I can rely on search more easily for notes applicable to multiple topics. So if something belongs to both “Business” and “Productivity”, I can just add it to productivity and make sure I add both the business and productivity tags.
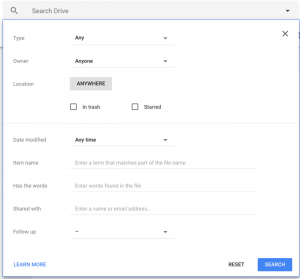
The great thing about having your notes in Google Drive is that you can take advantage of Google’s powerful search feature to find exactly what you need. For example, you can see below the options available in the search feature. You can search by file type, folder location, filename, and contents. With the structured note templates, you can find pretty much anything you need at the snap of a finger. For example, finding all the notes from Peter Drucker is simply a matter of writing in “Author: Peter Drucker” in the “Item Name” option shown below.
Daily Reviews Using Python and the Google Drive API
If you don’t have any programming knowledge, this commonplace book system will still serve you well and you don’t have to read on. But since this is a blog about hacking APIs and open data for the purposes of automation and competitive intelligence, there is more to my commonplace book system than simply adding documents to a Google Drive folder.
The commonplace book notes aren’t of much use if they’re just sitting in Google Docs unused, so I wanted to create a system of regular and automated review. Specifically, I wanted to receive an email every morning with 5 randomly selected notes from and review these notes a part of my daily routine. This helps incorporate the learning techniques of testing, spaced repetition, and varied practice. Regular review emails also give me a chance to edit notes if there are things I want to change or add.
You can find all of the code for this review system here. Here is an overview of what it does:
- Selects 5 documents at random across all the files in your commonplace book folder and subfolders
- Builds an email template with links to the five randomly selected commonplace book notes. It does this using the Jinja2 template engine.
- Sends the email of commonplace book notes to review to yourself (and any other recipients you want). See this previous blog post on how to write programs to send automated email updates.
I run the code on a DigitalOcean droplet, set on a cron job to run build_email.py at 7 am every day.
Before you try to run the code, you should follow steps 1 and 2 in this Python quick-start guide to turn on the Google Drive API and install the Google Drive client library. This will produce client_secret.json that you will need to place in the top directory of the code.
You’ll also need to make a few substitutions to placeholders in the code:
- Enter in your Gmail email and password in the file email_user_pass.json.
- Enter in the email that will be sending the email update and the list of recipients in the file emails.json.
- In build_email.py, you need to provide a value for COMMONPLACE_BOOK_FOLDER_ID. You can find this by looking in the URL when you navigate to your commonplace book folder in Google Drive.
- Install any of the required packages in build_email.py
You can customize the way that the email looks by modifying templates/email.html.
Note that this code is useful not just for this commonplace book system, but any system where you need to receive automated email updates that randomly select files in your Google Drive.
Just do it
Start your common book now. Even if you don’t know Python and can’t do the automated email update stuff, it doesn’t matter. This is just icing on the cake, and there are other ways you can review your commonplace book notes.
Trust me, you won’t regret taking the time to do this. The only thing you’ll regret is the fact that you didn’t start doing it 20 years ago.


